 |
Christian Kreibich†
Chris Kanich*
Kirill Levchenko*
Brandon Enright*
Geoffrey M. Voelker*
Vern Paxson†
Stefan Savage*
†International Computer Science Institute christian@icir.org, vern@cs.berkeley.edu *Dept. of Computer Science and Engineering {ckanich,klevchen,voelker,savage}@cs.ucsd.eduOn the Spam Campaign Trail
Berkeley, USA
University of California, San Diego, USA
bmenrigh@ucsd.edu
Over the last decade, unsolicited bulk email, or spam, has transitioned from a minor nuisance to a major scourge, adversely affecting virtually every Internet user. Industry estimates suggest that the total daily volume of spam now exceeds 120 billion messages per day [10]; even if the actual figure is 10 times smaller, this means thousands of unwanted messages annually for every Internet user on the planet. Moreover, spam is used not only to shill for cheap pharmaceuticals, but has also become the de facto delivery mechanism for a range of criminal endeavors, including phishing, securities manipulation, identity theft and malware distribution. This problem has spawned a multi-billion dollar anti-spam industry that in turn drives spammers to ever greater sophistication and scale. Today, even a single spam campaign may target hundreds of millions of email addresses, sent in turn via hundreds of thousands of compromised ``bot'' hosts, with polymorphic ``message templates'' carefully crafted to evade widely used filters.
However, while there is a considerable body of research focused on spam from the recipient's point of view, we understand considerably less about the sender's perspective: how spammers test, target, distribute and deliver a large spam campaign in practice. At the heart of this discrepancy is the limited vantage point available to most research efforts. While it is straightforward to collect individual spam messages at a site (e.g., via a ``spam trap''), short of infiltrating a spammer organization it is difficult to observe a campaign being orchestrated in its full measure. We believe ours is the first study to approach the problem from this direction.
In this paper, we explore a new methodology--distribution infiltration--for measuring spam campaigns from the inside. This approach is motivated by the observation that as spammers have migrated from open relays and open proxies to more complex malware-based ``botnet'' email distribution, they have unavoidably opened their infrastructure to outside observation. By hooking into a botnet's command-and-control (C&C) protocol, one can infiltrate a spammer's distribution platform and measure spam campaigns as they occur.
In particular, we present an initial analysis of spam campaigns conducted by the well-known Storm botnet, based on data we captured by infiltrating its distribution platform. We first look at the system components used to support spam campaigns. These include a work queue model for distributing load across the botnet, a modular campaign framework, a template language for introducing per-message polymorphism, delivery feedback for target list pruning, per-bot address harvesting for acquiring new targets, and special test campaigns and email accounts used to validate that new spam templates can bypass filters. We then also look at the dynamics of how such campaigns unfold. We analyze the address lists to characterize the targeting of different campaigns, delivery failure rates (a metric of address list ``quality''), and estimated total campaign sizes as extrapolated from a set of samples. From these estimates, one such campaign--focused on perpetuating the botnet itself--spewed email to around 400 million email addresses during a three-week period.
The research community has come relatively late to the study of spam, but in recent years there has been considerable attention focused on characterizing important aspects of the spam enterprise including address harvesting [13], the network behavior of spam relays [17], the hosting of scam sites [1] and advances in filter evasion [14]. Similarly, botnets themselves have enjoyed considerable attention from security researchers, including both case studies and analyses of size, number, activity, membership, and dynamics [4,18,6,15,21,2,11,16]. Here too, advances in defenses have provoked improvements in the underlying C&C technology. While early botnets depended exclusively on centralized C&C channels (typically IRC), modern botnets have developed increasingly sophisticated methods for obfuscating or minimizing their C&C exposure. Most recently, the Storm botnet has become the first that implements a directory service upon a distributed hash table [12,9,19]. In turn, this is used to bootstrap a custom C&C protocol that constructs a multi-level distribution hierarchy with a layer of message relays isolating the ``foot soldier'' bots, who blindly poll for commands, from a smaller set of servers that control them. While Storm represents the current technological front for spammers, at its core the basic methods are structurally the same as all spam distribution platforms of which we are aware.
Spammers divide their efforts into individual campaigns that are focused on a particular goal, whether it is selling a product, committing financial fraud, or distributing malware. Abstractly, we think of each spam campaign as consisting of a target list of email addresses--either harvested via crawling or malware or purchased outright via underground markets [5]--along with a set of subject and body text templates that are combined mechanically to create an individual message for each targeted address. A campaign may consist of one or more such runs and thus can vary in length from only a few hours to as long as months (as evidenced by Storm's e-card campaign of mid-2007 [3]). In turn, a spam campaign is executed by some distribution platform--typically a botnet--and this infrastructure can be reused by multiple campaigns (conversely there is anecdotal evidence of individual campaigns moving to using different botnets at different points in time). For reasons of scalability, this infrastructure is typically responsible for the task of evading textual spam filters and thus must generate each message algorithmically based on the campaign's text templates and a set of evasion rules, or macros. Also for scalability, the load of delivering a spam campaign must be balanced across the infrastructure. While the exact method can vary (e.g., pull-based vs push-based bots), the logic is nearly universal: a campaign is quantized into individual work requests--consisting of a subset of the target list and, optionally, updated templates and macros--that are distributed as updates from the spammer to the individual distribution nodes. Finally, the infrastructure can report back failures, allowing the spammer to weed out addresses from their target list that are not viable.
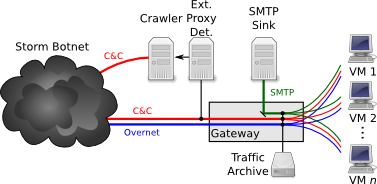
Our measurements come from both instrumentation and probing of the Storm botnet [12,20]. For instrumentation we run bots in controlled environments, and for probing we use crawling of Storm proxies, as described below. The key enabler for our infiltration effort was our development of the capability to analyze the different forms of Storm communication traffic, which required a significant reverse-engineering effort.
Storm employs a tiered coordination mechanism. At the lowest level, worker bots access a form of the Overnet peer-to-peer network to locate C&C proxy bots. Workers relay through the proxies requests for instructions and the results of executed commands, receiving from them their subsequent C&C. The proxies in turn interact with ``bullet-proof hosting'' sites under control of the botmaster. (Note that our work here focuses entirely on the proxy-based C&C mechanism; we do not employ any form of Overnet monitoring or probing.)
From late Dec. 2007 through
early Feb. 2008 we ran 16 instances of Storm bots![[*]](footnote.png) in virtual machines hosted on
VMware ESX 3 servers. Depending on the machines' configuration, these bots
could run as either workers or proxies. As workers, they would contact
remote proxies and receive instructions such as spamming directives.
As proxies, they would themselves be contacted by remote workers requesting
instructions, which they recorded and then relayed back into Storm.
in virtual machines hosted on
VMware ESX 3 servers. Depending on the machines' configuration, these bots
could run as either workers or proxies. As workers, they would contact
remote proxies and receive instructions such as spamming directives.
As proxies, they would themselves be contacted by remote workers requesting
instructions, which they recorded and then relayed back into Storm.
In addition, we analyze outgoing C&C requests from our workers in order to discover the external proxies to which they attempt to communicate. We feed these proxy identities to a custom crawler that mimics the presence of additional workers, repeatedly querying each active proxy for the latest spamming instructions.
Figure 1 summarizes the experimental setup (here, Overnet is shown only due to its use by our workers to locate proxies), and Table 1 summarizes the contents of data we gathered with the setup for our study. The first group of figures refers to measurements from the bot-based components of our setup (workers and proxies we ran in our controlled environment). Here, the term ``External'' refers to information sent to us by remote workers contacting our local proxies; ``Total'' refers to volumes summed across both such external reports plus the activities of our local workers. (Our local workers do not generate meaningful harvesting figures, which they are unable to perform in an effective fashion. Also, our local workers did not attempt to send spam until Jan 7.) The second group of figures refers to measurements extracted from the crawler component of our setup.
|
In this section we briefly describe how Storm worker bots are instructed to construct the individual spam messages that they then attempt to propagate.
In general, workers acquire new tasks in a pull-based fashion, by
actively requesting update messages from their proxies. (Similarly, they
send back delivery and harvest reports asynchronously, at a time of
their choosing.)
Update messages consist of three sections, each possibly empty (if modifying
elements of a previous update).
These are: (![]() ) template material;
(
) template material;
(![]() ) sets of dictionaries containing raw text material to substitute
into templates; and (
) sets of dictionaries containing raw text material to substitute
into templates; and (![]() ) lists of target email addresses.
These lists typically provide roughly 1,000 addresses per update message.
Templates and target
lists are labeled with small integers, which we term a
slot. Spam constructed from a given template is sent to targets
in lists labeled with the corresponding slot numbers.
Delivery reports mirror the target list structure of update messages,
with addresses listed in full upon success, and otherwise an error code
in its stead, reporting the cause of failure.
Harvest reports contain zero or more addresses, not further
structured.
) lists of target email addresses.
These lists typically provide roughly 1,000 addresses per update message.
Templates and target
lists are labeled with small integers, which we term a
slot. Spam constructed from a given template is sent to targets
in lists labeled with the corresponding slot numbers.
Delivery reports mirror the target list structure of update messages,
with addresses listed in full upon success, and otherwise an error code
in its stead, reporting the cause of failure.
Harvest reports contain zero or more addresses, not further
structured.
For spam construction, Storm implements a fairly elaborate template language, supporting formatting macros with input arguments for text insertion and formatting, generation of random numbers, computation of MTA message identifiers, dates, and reuse of results of previous macro invocations. Macros are delineated by a start marker ``[fontfamily=courier,fontseries=b]+and a corresponding end marker ``[fontfamily=courier,fontseries=b]+^We use parentheses below instead of Storm's markup to ease readability. A single letter after the initial marker identifies the macro's functionality. It is followed by zero or more macro input arguments, which may consist of the output of nested macros. We verified the meaning of the different macro types seen in real traffic by feeding suitably crafted templates to the workers in our setup and observing the resulting spam they attempted to send. In addition, we also tested the letters of the alphabet not encountered in real templates, to see whether they would provide any functionality. This way, we discovered ten additional language features. Table 2 summarizes the language features we identified.
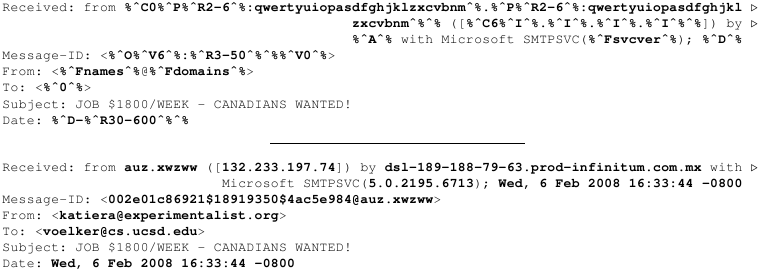
Figure 2 shows the header part of a template as used
by Storm, together with the resulting email message header. The from-part of the Received header serves as a good example of
macro use. The content is constructed as follows:
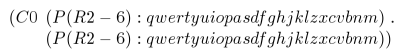
|
We now turn to characterizing the observed behavior of workers as they construct, transmit, and report back on spam batches. Note that characterizations can reflect observation of our local workers; remote workers that reported to our local proxies; or remote proxies sending instructions to our crawler. When unclear from context, we clarify which subsets of our data apply to each discussion.
Overall, we observed bots sending spam to 67M target addresses with very little redundancy: over 65M of the addresses were unique. The target addresses were heavily concentrated (60%) in the .com TLD, reflecting a similar concentration in harvested addresses. We also observed over 170K templates (22K unique) used by the bots to generate spam, far more than the number of campaigns observed. The high template dynamism suggests constant tuning by the spammers to continually subvert filtering.
In the remainder of this section, we discuss preliminary measurements of the bot life-cycle (the dynamics of how bots send spam), delivery efficacy (how many targets actually have mail sent to them), the dictionaries used to programatically construct messages, the prevalence of different kinds of campaigns, address harvesting behavior, and the presence of test accounts employed by the botmaster.
Worker bots begin searching for proxies (via Overnet) upon boot-up, sending a request for an update message upon successful contact with one. (The worker then attempts a TCP port 25 connectivity check to one of Google's SMTP servers. However, its subsequent behavior does not appear to change whether or not the check succeeds.) Upon receiving an update with spam instructions, the worker then attempts to send a spam to each member of target lists in slots for which the bot has templates. It targets each address only once per occurrence in the list, working through it in sequence. The only pauses in spamming occur when a worker runs out of targets, at which point spamming goes idle until the worker next requests and receives additional targets.
We analyzed 72 bot lifespans to better understand spamming rates and bot reliability. On average, it takes our worker bots just over 4 min after boot-up until receiving the first update message. We have found that workers are short-lived: they generally fall silent (on both Overnet as well as C&C) within 24h of start-up, and on average remain functional only for a little under 4 hr. A reboot spurs them to resume their activity. This observation can explain the tendency of spam sent by the Botnet to peak in the mid-morning hours of the local timezone, shortly after infected machines are powered on [8]. The overall average spamming rate was 152 messages per minute, per bot.
|
We analyzed a total of 30,186 delivery reports that our proxy bots received from remote workers. This allowed us to form an estimate of how successfully Storm delivers spam. Delivery succeeds for only 1/6th of the target addresses provided. Understanding the causes of failure required investigation of the error status codes reported by the bots. By combining reverse-engineering of the binary with failure-introducing configurations of our internal setup (DNS failures, SMTP server refusal, etc.) at different stages of the spam-delivery process, we could observe the codes returned by our local workers when encountering these difficulties.
We find that DNS lookup failures account for about 10% of reported failures; 8% of delivery attempts fail to establish a TCP connection to the SMTP server, 28% fail because the SMTP session does not begin with the expected 220 banner, 1% fail due to errors in the HELO stage, 18% at the RCPT TO stage, 14% at the MAIL FROM stage, and 4% at the DATA stage.
Storm's spamming operation relies heavily on the use of F-macros to generate polymorphic messages and to create URLs for the recipients to click on. In the bot-based dataset, we observed a total of 356,279 dictionaries, clustered under 33 different names. Dictionaries repeat heavily, with only 2% being unique across the overall set of dictionaries bearing the same name.
The group with the least redundancy is ``linksh'' (14% unique), whose purpose is Storm's self-preservation: the spam content includes the raw IP addresses of proxy bots that serve up web content designed to trick the email recipient into downloading and executing a Storm executable.
Table 3 summarizes the main aspects of the dictionaries we observed.
| TOPIC | FRACTION |
| Self-propagation | 22% |
| Pharmaceutical | 22% |
| Stocks | 11% |
| Job offer | 1% |
| Phishing | 1% |
| Unknown image | 39% |
| Unknown other | 4% |
|
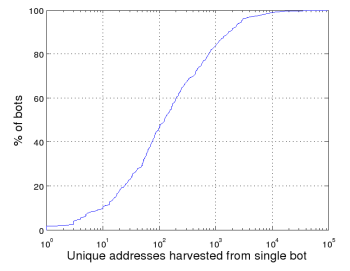
Our local proxies received a total of 272,546 harvest reports from 522 remote workers. Only 10% of these contained any addresses.
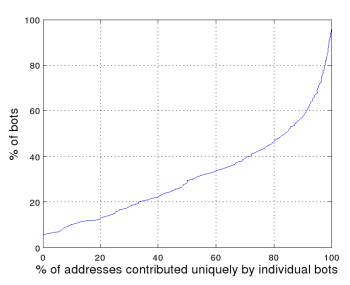
The reports reflected a total harvest of 929,976 email addresses, of which 463,580 were unique. Figure 3(a) shows the distribution of overall harvest size per bot, with duplicates removed. Workers on average reported nearly a thousand distinct addresses, with the top harvest--seemingly a regular home customer with an Indian ISP--contributing 96,053 addresses. In addition, as seen in Figure 3(b), addresses reported by individual workers are often unique across the entire harvest (that is, had that worker not reported, those addresses would not have otherwise been reaped). For example, for 50% of the workers, 84% or more of their reported addresses were not otherwise harvested.
Unsurprisingly, the most frequently harvested domains all correspond to major email services: hotmail.com, yahoo.com, aol.com, mail.ru, gmail.com, mynet.com, msn.com, rediffmail.com, etc. These for the most part closely match the most prevalent domains in email address lists, as well.
However, about 10% of the harvested addresses do not correspond to a valid top-level domain. Frequent errors include .gbl, .jpg, .msn, .hitbox, .yahoo, .com0, .dll; clearly, some of these reflect inadequate pattern-matching when scouring the local filesystem, or files that contain slightly mangled addresses. Interestingly, unlike for correctly harvested addresses, the prevalent patterns for error here differ to a greater degree from the errors seen in address lists used during campaigns, suggesting that some additional pruning/filtering is likely applied to harvested addresses.
We also note the possibility of seeding machines with honeytoken addresses encoded to uniquely identify the machines on which they are planted. Unlike harvesting errors, these addresses could look completely legitimate, and in fact would be functional; any subsequent use of them would would then strongly indicate that the machine encoded within the address had been compromised and its file system scoured for email harvesting.
(Note: we have left details vague in this section because the specifics have implications for current law enforcement activity.)
In our analysis we uncovered the presence of a template slot which sent email to a set of just 4 email addresses. Upon inspecting the message template, we discovered that a modified version of the spam body appeared a few hours later, again sent to the same set of addresses. All four addresses have a similar structure and correspond to large email providers. We speculate that the botmaster uses these addresses to test the degree to which the structure of their new campaign is vulnerable to detection by the spam filters that large sites employ. This possibility suggests an opportunity for a form of counter-intelligence (similar in spirit to that employed in [18]): perhaps at the vantage point of such a provider we can detect the pattern of an initial message sent to a small number of addresses, and flagged as spam, followed by a subsequent similar message sent more broadly. Such an approach might be able to both detect the onset of a new spam campaign and help unmask the spammer via their access to the test account.
Both estimation methods are grounded in a set of statistical assumptions about the underlying sampling process, namely that:
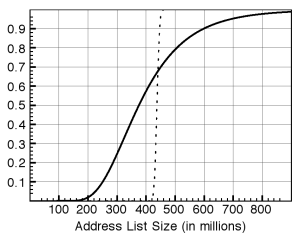 |
For our analysis, we use the Bayesian multiple-capture model described by Gazey and Staley [7]. In this setting, email addresses are the individual animals, the complete mailing list is the population, and each batch of 900-1,000 addresses retrieved with a template is a sample of the population. We use two estimators: the standard estimator described in [7], which assumes that all addresses are chosen independently, and a modified estimator that only requires that the first addresses of the batch included with each template be independent. We refer to them as the aggressive and conservative estimators, respectively. Figure 4 shows the estimate CDF for both. The aggressive estimator estimate is 437 million and the conservative estimator estimate is 376 million, with the 95% confidence interval for the conservative estimate between 206 million and 790 million addresses.
Over the campaign time
period (late 2007 to early 2008), a total of ![]() distinct addresses
received wormsubj. Of those, only
distinct addresses
received wormsubj. Of those, only ![]() occurred in the list of
occurred in the list of
![]() addresses retrieved by our crawler for this campaign. This
gives an estimate of the total list size of approximately 677 million
addresses, which is just within the 95% confidence interval of the conservative estimator. The 95% confidence interval for the Sample Coverage estimator itself is 410 million to 1,880 million. Because this estimator is unreliable when
addresses retrieved by our crawler for this campaign. This
gives an estimate of the total list size of approximately 677 million
addresses, which is just within the 95% confidence interval of the conservative estimator. The 95% confidence interval for the Sample Coverage estimator itself is 410 million to 1,880 million. Because this estimator is unreliable when ![]() is small, we consider it a ``sanity check'' for the Mark and Recapture estimate.
is small, we consider it a ``sanity check'' for the Mark and Recapture estimate.
Even though these problems might each be accommodated to varying degrees, the opportunities of instead measuring spam at its source are strong. An ideal solution would be to infiltrate spam organizations themselves, observe the address lists they construct, the commands they deliver, and the feedback they receive. However, as few in the research community have a strong aptitude (and legal standing) for covert operations, we believe the next best opportunity is presented by the networks of bots used to distribute the vast majority of today's spam--distribution infiltration. In this setting, reverse-engineering can suffice to infiltrate the distribution infrastructure and ``drink from the spam firehose'' at will. In this paper, we have demonstrated this approach in the context of the Storm network, extracting millions of samples pre-sorted by campaign, and observing the same intelligence that the botnet delivers to the spammers themselves. In so doing, we have documented a number of interesting aspects of such campaigns, including automated error reporting, address harvesting, a sophisticated template language, and dedicated test accounts. We have further constructed a well-grounded estimate of the size of one of the address lists in the hundreds of millions. While both our data and our experiences are preliminary, we believe the underlying technique is sound, and offers an unprecedented level of detail about spammer activities--virtually impossible to otherwise obtain using traditional methods.
Our thanks to Joe Stewart of Secureworks for offering his insight into the workings of Storm, Erin Kenneally for advising us on legal issues, and to Gabriel Lawrence and Jim Madden for supporting this activity on UCSD's systems and networks. Our data collection was made possible by generous support and gifts from ESnet, the Lawrence Berkeley National Laboratory, Cisco, Microsoft Research, VMware, HP, Intel and UCSD's Center for Networked Systems, for which we are very grateful. This work was made possible by the National Science Foundation grants NSF-0433702 and NSF-0433668. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors or originators and do not necessarily reflect the views of the National Science Foundation.
This document was generated using the LaTeX2HTML translator Version 2002-2-1 (1.70) and followed by a boatload of manual tweaking to correct all the generated nonsense.
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -split 0 -show_section_numbers -local_icons -no_navigation paper.tex
The translation was initiated by Christian Kreibich on 2008-04-04