A First Look at Modern Enterprise Traffic
Ruoming Pang^,
Mark Allman+,
Mike Bennett*, Jason Lee*,
Vern Paxson+*,
Brian Tierney*
^Princeton University, +International Computer Science Institute,
*Lawrence Berkeley National Laboratory (LBNL)
Abstract:
While wide-area Internet traffic has been heavily studied for many years, the characteristics of traffic inside Internet enterprises remain almost wholly unexplored. Nearly all of the studies of enterprise traffic available in the literature are well over a decade old and focus on individual LANs rather than whole sites. In this paper we present a broad overview of internal enterprise traffic recorded at a medium-sized site. The packet traces span more than 100 hours, over which activity from a total of several thousand internal hosts appears. This wealth of data—which we are publicly releasing in anonymized form—spans a wide range of dimensions. While we cannot form general conclusions using data from a single site, and clearly this sort of data merits additional in-depth study in a number of ways, in this work we endeavor to characterize a number of the most salient aspects of the traffic. Our goal is to provide a first sense of ways in which modern enterprise traffic is similar to wide-area Internet traffic, and ways in which it is quite different.
Table 1 provides an overview of the collected packet traces. The “per tap” field indicates the number of traces taken on each monitored router port, and Snaplen gives the maximum number of bytes captured for each packet. For example, D0 consists of full-packet traces from each of the 22 subnets monitored once for 10 minutes at a time, while D1 consists of 1 hour header-only (68 bytes) traces from the 22 subnets, each monitored twice (i.e., two 1-hour traces per subnet).
D0 D1 D2 D3 D4 Date 10/4/04 12/15/04 12/16/04 1/6/05 1/7/05 Duration 10 min 1 hr 1 hr 1 hr 1 hr Per Tap 1 2 1 1 1-2 # Subnets 22 22 22 18 18 # Packets 17.8M 64.7M 28.1M 21.6M 27.7M Snaplen 1500 68 68 1500 1500 Mon. Hosts 2,531 2,102 2,088 1,561 1,558 LBNL Hosts 4,767 5,761 5,210 5,234 5,698 Remote Hosts 4,342 10,478 7,138 16,404 23,267
Table 1: Dataset characteristics.
In addition to the known internal scanners, we identify additional scanning traffic using the following heuristic. We first identify sources contacting more than 50 distinct hosts. We then determine whether at least 45 of the distinct addresses probed were in ascending or descending order. The scanners we find with this heuristic are primarily external sources using ICMP probes, because most other external scans get blocked by scan filtering at the LBNL border. Prior to our subsequent analysis, we remove traffic from sources identified as scanners along with the 2 internal scanners. The fraction of connections removed from the traces ranges from 4–18% across the datasets. A more in-depth study of characteristics that the scanning traffic exposes is a fruitful area for future work.
D0 D1 D2 D3 D4 Bytes (GB) 13.12 31.88 13.20 8.98 11.75 TCP 66% 95% 90% 77% 82% UDP 34% 5% 10% 23% 18% ICMP 0% 0% 0% 0% 0% Conns (M) 0.16 1.17 0.54 0.75 1.15 TCP 26% 19% 23% 10% 8% UDP 68% 74% 70% 85% 87% ICMP 6% 6% 8% 5% 5%
Table 3: Fraction of connections and bytes utilizing various transport protocols.
Category Protocols backup Dantz, Veritas, “connected-backup” bulk FTP, HPSS SMTP, IMAP4, IMAP/S, POP3, POP/S, LDAP interactive SSH, telnet, rlogin, X11 name DNS, Netbios-NS, SrvLoc net-file NFS, NCP net-mgnt DHCP, ident, NTP, SNMP, NAV-ping, SAP, NetInfo-local streaming RTSP, IPVideo, RealStream web HTTP, HTTPS windows CIFS/SMB, DCE/RPC, Netbios-SSN, Netbios-DGM misc Steltor, MetaSys, LPD, IPP, Oracle-SQL, MS-SQL
Table 4: Application categories and their constituent protocols.
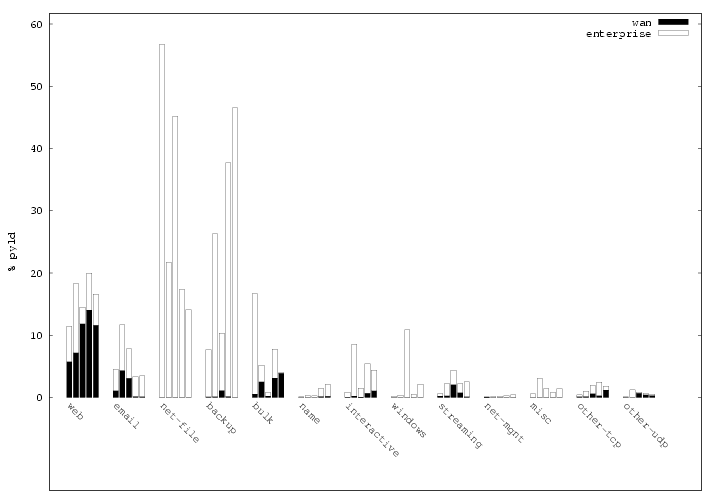
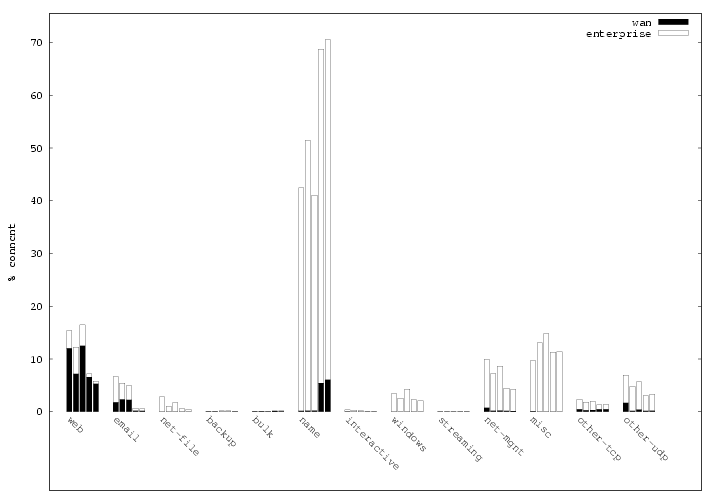
Next we break down the traffic by application category. We group TCP and UDP application protocols as shown in Table 4. The table groups the applications together based on their high-level purpose. We show only those distinguished by the amount of traffic they transmit, in terms of packets, bytes or connections (we omit many minor additional categories and protocols). In § 5 we examine the characteristics of a number of these application protocols.
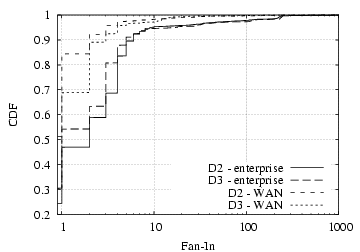
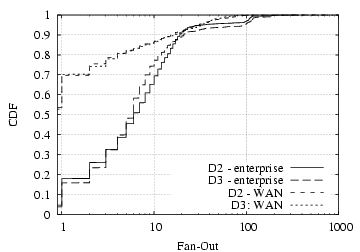
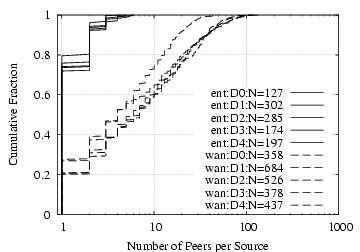
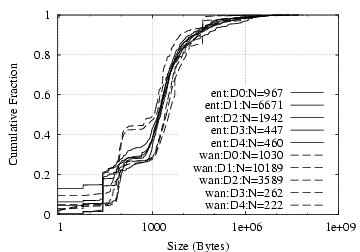
Figure 2 shows the distribution of fan-in and fan-out for D2 and D3.2 We observe that for both fan-in and fan-out, the hosts in our datasets generally have more peers within the enterprise than across the WAN, though with considerable variability. In particular, one-third to one-half of the hosts have only internal fan-in, and more than half with only internal fan-out — much more than the fraction of hosts with only external peers. This difference matches our intuition that local hosts will contact local servers (e.g., SMTP, IMAP, DNS, distributed file systems) more frequently than requesting services across the wide-area network, and is also consistent with our observation that a wider variety of applications are used only within the enterprise.
In this section we examine transport-layer and application-layer characteristics of individual application protocols. Table 5 provides a number of examples of the findings we make in this section.
§ 5.1.1 Automated HTTP client activities constitute a significant fraction of internal HTTP traffic. § 5.1.2 IMAP traffic inside the enterprise has characteristics similar to wide-area email, except connections are longer-lived. § 5.1.3 Netbios/NS queries fail nearly 50% of the time, apparently due to popular names becoming stale. § 5.2.1 Windows traffic is intermingled over various ports, with Netbios/SSN (139/tcp) and SMB (445/tcp) used interchangeably for carrying CIFS traffic. DCE/RPC over “named pipes”, rather than Windows File Sharing, emerges as the most active component in CIFS traffic. Among DCE/RPC services, printing and user authentication are the two most heavily used. § 5.2.2 Most NFS and NCP requests are reading, writing, or obtaining file attributes. § 5.2.3 Veritas and Dantz dominate our enterprise's backup applications. Veritas exhibits only client → server data transfers, but Dantz connections can be large in either direction.
Table 5: Example application traffic characteristics.
Automated Clients: In internal Web transactions we find three activities not originating from traditional user-browsing: scanners, Google bots, and programs running on top of HTTP (e.g., Novell iFolder and Viacom Net-Meeting). As Table 6 shows, these activities are highly significant, accounting for 34–58% of internal HTTP requests and 59–96% of the internal data bytes carried over HTTP. Including these activities skews various HTTP characteristics. For instance, both Google bots and the scanner have a very high “fan-out”; the scanner provokes many more “404 File Not Found” HTTP replies than standard web browsing; iFolder clients use POST more frequently than regular clients; and iFolder replies often have a uniform size of 32,780 bytes. Therefore, while the presence of these activities is the biggest difference between internal and wide-area HTTP traffic, we exclude these from the remainder of the analysis in an attempt to understand additional differences.
Request Data D0/ent D3/ent D4/ent D0/ent D3/ent D4/ent Total 7098 16423 15712 602MB 393MB 442MB scan1 20% 45% 19% 0.1% 0.9% 1% google1 23% 0.0% 1% 45% 0.0% 0.1% google2 14% 8% 4% 51% 69% 48% ifolder 1% 0.2% 10% 0.0% 0.0% 9% All 58% 54% 34% 96% 70% 59%
Table 6: Fraction of internal HTTP traffic from automated clients.
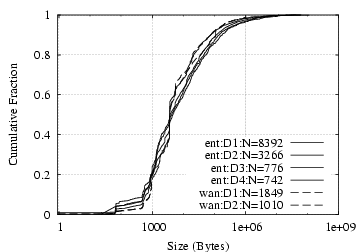
Fan-out: Figure 3 shows the distribution of fan-out from monitored clients to enterprise and WAN HTTP servers. Overall, monitored clients visit roughly an order of magnitude more external servers than internal servers. This seems to differ from the finding in § 4 that over all traffic clients tend to access more local peers than remote peers. However, we believe that the pattern shown by HTTP transactions is more likely to be the prevalent application-level pattern and that the results in § 4 are dominated by the fact that clients access a wider variety of applications. This serves to highlight the need for future work to drill down on the first, high-level analysis we present in this paper.
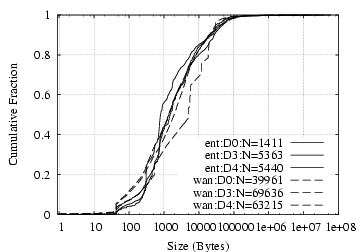
HTTP Responses: Figure 4 shows the distribution of HTTP response body sizes, excluding replies without a body. We see no significant difference between internal and WAN servers. The short vertical lines of the D0/WAN curve reflect repeated downloading of javascripts from a particular website. We also find that about half the web sessions (i.e., downloading an entire web page) consist of one object (e.g., just an HTML page). On the other hand 10–20% of the web sessions in our dataset include 10 or more objects. We find no significant difference across datasets or server location (local or remote).
Request Data enterprise wan enterprise wan text 18% – 30% 14% – 26% 7% – 28% 13% – 27% image 67% – 76% 44% – 68% 10% – 34% 16% – 27% application 3% – 7% 9% – 42% 57% – 73% 33% – 60% Other 0.0% – 2% 0.3% – 1% 0.0% – 9% 11% – 13%
Table 7: HTTP reply by content type. “Other” mainly includes audio, video, and multipart.
HTTP/SSL: Our data shows no significant difference in HTTPS traffic between internal and WAN servers. However, we note that in both cases there are numerous small connections between given host-pairs. For example, in D4 we observe 795 short connections between a single pair of hosts during an hour of tracing. Examining a few at random shows that the hosts complete the SSL handshake successfully and exchange a pair of application messages, after which the client tears down the connection almost immediately. As the contents are encrypted, we cannot determine whether this reflects application level fail-and-retrial or some other phenomenon.
Email is the second traffic category we find prevalent in both internally and over the wide-area network. As shown in Table 8, SMTP and IMAP dominate email traffic, constituting over 94% of the volume in bytes. The remainder comes From LDAP, POP3 and POP/SSL. The table shows a transition from IMAP to IMAP/S (IMAP over SSL) between D0 and D1, which reflects a policy change at LBNL restricting usage of unsecured IMAP.
We next focus on characteristics of email traffic that are similar across network type.
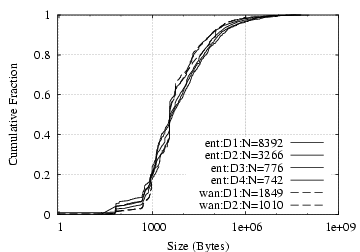
Flow Size: Internal and wide-area email traffic does not show significant differences in terms of connection sizes, as shown in Figure 6. As we would expect, the traffic volume of SMTP and IMAP/S is largely unidirectional (to SMTP servers and to IMAP/S clients), with traffic in the other direction largely being short control messages. Over 95% of the connections to SMTP servers and to IMAP/S clients remain below 1 MB, but both cases have significant upper tails.
Netbios/SSN Success Rate: After a connection is established, a Netbios/SSN session goes through a handshake before carrying traffic. The success rate of the handshake (counting the number of distinct host-pairs) is 89–99% across our datasets. Again, the failures are not due to any single client or server, but are spread across a number of hosts. The reason for these failures merits future investigation.
Host Pairs Netbios/SSN CIFS Endpoint Mapper Total 595 – 1464 373 – 732 119 – 497 Successful 82% – 92% 46% – 68% 99% – 100% Rejected 0.2% – 0.8% 26% – 37% 0.0% – 0.0% Unanswered 8% – 19% 5% – 19% 0.2% – 0.8%
Table 9: Windows traffic connection success rate (by number of host-pairs, for internal traffic only)
DCE/RPC Functions: Since DCE/RPC constitutes an important part of Windows traffic, we further analyze these calls over both CIFS pipes and stand-alone TCP/UDP connections. While we include all DCE/RPC activities traversing CIFS pipes, our analysis for DCE/RPC over stand-alone TCP/UDP connections may be incomplete for two reasons. First, we identify DCE/RPC activities on ephemeral ports by analyzing Endpoint Mapper traffic. Therefore, we will miss traffic if the mapping takes place before our trace collection begins, or if there is an alternate method to discover the server's ports (though we are not aware of any other such method). Second, our analysis tool currently cannot parse DCE/RPC messages sent over UDP. While this may cause our analysis to miss services that only use UDP, DCE/RPC traffic using UDP accounts for only a small fraction of all DCE/RPC traffic.
Request Data D0/ent D3/ent D4/ent D0/ent D3/ent D4/ent Total 49120 45954 123607 18MB 32MB 198MB SMB Basic 36% 52% 24% 15% 12% 3% RPC Pipes 48% 33% 46% 32% 64% 77% Windows File Sharing 13% 11% 27% 43% 8% 17% LANMAN 1% 3% 1% 10% 15% 3% Other 2% 0.6% 1.0% 0.2% 0.3% 0.8%
Table 10: CIFS command breakdown. “SMB basic” includes the common commands shared by all kinds of higher level applications: protocol negotiation, session setup/tear-down, tree connect/disconnect, and file/pipe open.
Request Data D0/ent D3/ent D4/ent D0/ent D3/ent D4/ent Total 14191 13620 56912 4MB 19MB 146MB NetLogon 42% 5% 0.5% 45% 0.9% 0.1% LsaRPC 26% 5% 0.6% 7% 0.3% 0.0% Spoolss/WritePrinter 0.0% 29% 81% 0.0% 80% 96% Spoolss/other 24% 34% 10% 42% 14% 3% Other 8% 27% 8% 6% 4% 0.6%
Table 11: DCE/RPC function breakdown.
NFS and NCP3 comprise the two main network file system protocols seen within the enterprise and this traffic is nearly always confined to the enterprise.4 We note that several trace-based studies of network file system characteristics have appeared in the filesystem literature (e.g., see [7] and enclosed references). We now investigate several aspects of network file system traffic.
Breakdown by Request Type: Table 13 and 14 show that in both NFS and NCP, file read/write requests account for the vast majority of the data bytes transmitted, 88–99% and 92–98% respectively. In terms of the number of requests, obtaining file attributes joins read and write as a dominant function. NCP file searching also accounts for 7–16% of the requests (but only 1–4% of the bytes). Note that NCP provides services in addition to remote file access, e.g., directory service (NDS), but, as shown in the table, in our datasets NCP is predominantly used for file sharing.
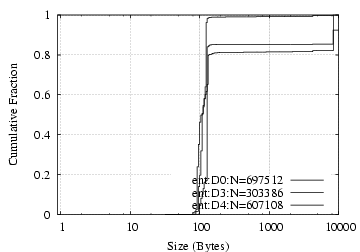
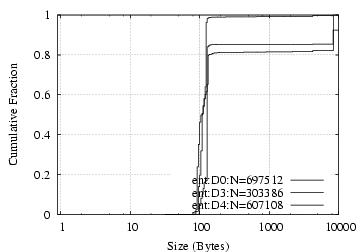
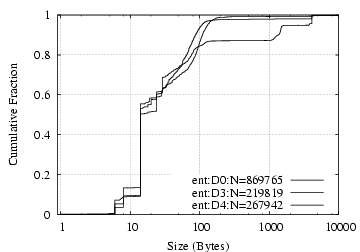
Request Data D0/ent D3/ent D4/ent D0/ent D3/ent D4/ent Total 697512 303386 607108 5843MB 676MB 1064MB Read 70% 25% 1% 64% 92% 6% Write 15% 1% 19% 35% 2% 83% GetAttr 9% 53% 50% 0.2% 4% 5% LookUp 4% 16% 23% 0.1% 2% 4% Access 0.5% 4% 5% 0.0% 0.4% 0.6% Other 2% 0.9% 2% 0.1% 0.2% 1%
Table 13: NFS requests breakdown.
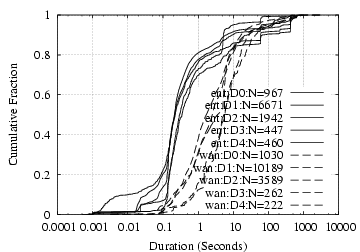
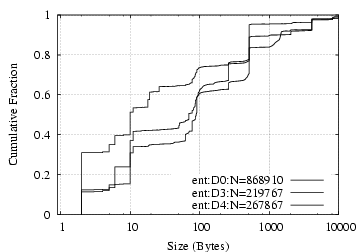
Request/Reply Data Size Distribution: As shown in Figure 8(a,b), NFS requests and replies have clear dual-mode distributions, with one mode around 100 bytes and the other 8 KB. The latter corresponds to write requests and read replies, and the former to everything else. NCP requests exhibit a mode at 14 bytes, corresponding to read requests, and each vertical rise in the NCP reply size figure corresponds to particular types of commands: 2-byte replies for completion codes only (e.g. replying to “WriteFile” or reporting error), 10 bytes for “GetFileCurrentSize”, and 260 bytes for (a fraction of) “ReadFile” requests.
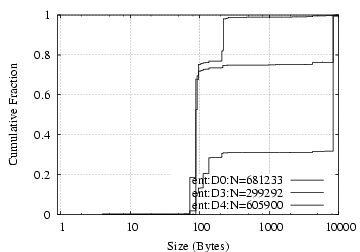
Request Data D0/ent D3/ent D4/ent D0/ent D3/ent D4/ent Total 869765 219819 267942 712MB 345MB 222MB Read 42% 44% 41% 82% 70% 82% Write 1% 21% 2% 10% 28% 11% FileDirInfo 27% 16% 26% 5% 0.9% 3% File Open/Close 9% 2% 7% 0.9% 0.1% 0.5% File Size 9% 7% 5% 0.2% 0.1% 0.1% File Search 9% 7% 16% 1% 0.6% 4% Directory Service 2% 0.7% 1% 0.7% 0.1% 0.4% Other 3% 3% 2% 0.2% 0.1% 0.1%
Table 14: NCP requests breakdown.
We find three types of backup traffic, per Table 15: two internal traffic giants, Dantz and Veritas, and a much smaller, “Connected” service that backs up data to an external site. Veritas backup uses separate control and data connections, with the data connections in the traces all reflecting one-way, client-to-server traffic. Dantz, on the other hand, appears to transmit control data within the same connection, and its connections display a degree of bi-directionality. Furthermore, the server-to-client flow sizes can exceed 100 MB. This bi-directionality does not appear to reflect backup vs. restore, because it exists not only between connections, but also within individual connections—sometimes with tens of MB in both directions. Perhaps this reflects an exchange of fingerprints used for compression or incremental backups or an exchange of validation information after the backup is finished. Alternatively, this may indicate that the protocol itself may have a peer-to-peer structure rather than a strict server/client delineation. Clearly this requires further investigation with longer trace files.
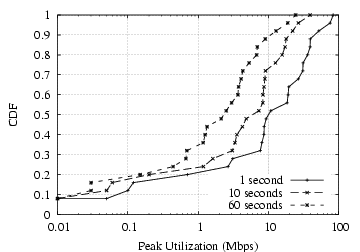
Due to limited space, we discuss only D4, although the other datasets provide essentially the same insights about utilization. Figure 9(a) shows the distribution of the peak bandwidth usage over 3 different timescales for each trace in the D4 dataset. As expected, the plot shows the networks to be less than fully utilized at each timescale. The 1 second interval does show network saturation (100 Mbps) in some cases. However, as the measurement time interval increases the peak utilization drops, indicating that saturation is short-lived.
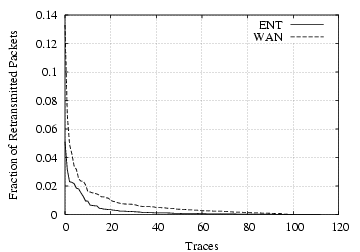
We found a number of spurious 1 byte retransmissions due to TCP keep-alives by NCP and SSH connections. We exclude these from further analysis because they do not indicate load imposed on network elements. Figure 10 shows the remaining retransmission rate for each trace in all our datasets, for both internal and remote traffic. In the vast majority of the traces, the retransmission rate remains less than 1% for both. In addition, the retransmission rate for internal traffic is less than that of traffic involving a remote peer, which matches our expectations since wide-area traffic traverses more shared, diverse, and constrained networks than does internal traffic. (While not shown in the Figure, we did not find any correlation between internal and wide-area retransmission rates.)
This document was translated from LATEX by HEVEA.